Django Async vs FastAPI vs WSGI Django: Choice of ML/DL Inference Servers — Answering some burning questions
Is it time to make the switch to FastAPI from Django? Read ahead to decide on your own.
With FastAPI gaining momentum and popularity with Async support, we wanted to move from Django to FastAPI. Hell.. we did move some of our inference engines to FastAPI. And like anyone else, we were facing some burning questions, is it worth moving to FastAPI leaving behind Django ORM and Django’s inbuilt admin dashboard support.
To answer these questions, we present findings from our benchmark testing and comparison of ML/DL Inference server with Tensorflow 2.0 on Django Synchronous DRF server, Django-Async Server, and FastAPI. The results were not something, that we expected… nor anyone expected!!!
Server Setup
AWS EC2 t2.micro free tier instance with 1 GB RAM and 1 vCPU. To make a fair comparison, all instances have the exact same version of libraries and the same configuration of server workers. Async Django and FastAPI apps are served using NGINX, Gunicorn, and Uvicorn. Whereas the normal Django app needs only NGINX and UWSGI.

Tensorflow Inference Network and Model
All servers are serving MOBILENET_v2 model from tensorflow.keras.applications.mobilenet_v2. This one is just 14 odd MB and doesn't crash the microserver. We did test using Resnet50 and the Sync Django version kept on crashing due to lack of memory. So, had to choose a smaller model.
Stress Test Setup using Locust
Locust was used to spawn multiple users and requests. All requests request prediction of the inference engine. 3 cases were benchmarked:
[A] 20 Users with Spawn rate of 20 spawns/sec: Referred as 20U-20SPS in the rest of the article. This represents optimal load case for the current server config.
[B] 100 Users with Spawn rate of 100 spawns/sec: Referred as 100U-100SPS. This represents near-peak load case for the current server config.
[C] 200 Users with Spawn rate of 200 Spawns/sec: Referred as 200U-200SPS. This represents above-peak overload case for the current server config.
Results: The showdown
- Requests Failures Per Second and Failures %:
All three frameworks could handle 20 Users 20U-20SPS without any issues and without any errors in a single t2.micro instance. In 100 Users Case, Django Async and Django Sync frameworks both could handle without any errors. However, FastAPI showed 1.4 Request Failures/Sec with 13% of requests leading to failures with 502 errors. This was a big surprise — this was not expected. Although, FastAPI momentarily achieves higher requests per second compared to the other two, but starts dropping requests thereafter. In 200 users' case, Django Sync had 59.1 Request Failures/Sec with a massive 88.2% of requests leading to 502 errors. FastAPI had 5.1 Request Failures/Sec with 39.6% packets not being served. Async Django on the other hand, had only 1.7 Request Failures/Sec with only 15.8% failures. That would keep the effective successful serving rate of 168.4 Users on a t2.micro instance.

WINNER: Async Django — Handles comparatively more number of users and leads to a lower error rate.
2. Requests Per Second (RPS):
Django Sync archives a similar performance with an average of 10.4 RPS in 20 and 100 Users Case. It reduces to 7.9 successful RPS in 200 Users' case with 88% of requests not being served.
FastAPI wins against both: with 3% better than Async and 7.7% better than Sync Django in the 20U-20SPS case, with 11.2 RPS (See Fig 2 and Fig 3). In 100 Users case, FastAPI achieves a 14 RPS momentarily before failures start occurring. Due to this, the effective successful RPS is brought down to 9.3 RPS for the 100U-100SPS case. In 200 Users' case, the effective RPS is less than that of Django Sync and lags behind Django Async by almost 17%.
Django Async has consistent 10.9 RPS in both 20U and 100U case, with 0 error rate. In the 200 Users case, it outshines both frameworks by a considerable amount. The effective successful RPS is 9.3 RPS with 15.8% failures. Django Async has a 5–17% improvement compared to Django Sync. Compared to FastAPI, under high traffic, Django Async seems to work better with 15–17% improvement.
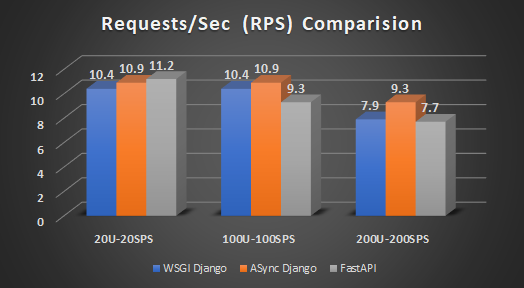
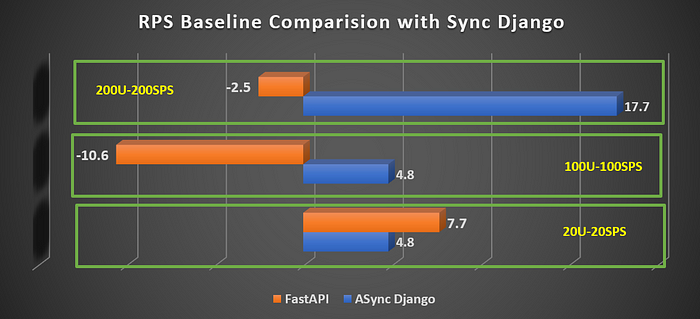
RPS WINNER: Async Django — Handles comparatively more number of users and serves a lot of requests per second and leads to a lower error rate.
3. Average Response Time (ART):
20U20SPS: All three frameworks' average response times are around 1.8s to 1.9s range, with FastAPI having a slightly better response time of 1772 ms compared to 1816 of Async Django. FastAPI has a 6.83% better response time than Sync Django, but only a 2.3% improvement compared to Async Django.
100U100SPS: In this case, all frameworks differ just by 100–250ms, with Django Async faring better than others with 8.871ms ART. A 5x increase in load increased the response by approx 5x.
200U200SPS: In this case, Sync Django ART was shown as 2299 ms. However, this is due to locust counting the failure response also. The failure responses come early because the webserver cannot process the request, and NGINX responds with 502 errors. Since sync Django has almost 90% error, the ART values cannot be used reliably. The same is the case for FastAPI with a 40% error rate. The max response times are 19.6 Sec for Sync Django, 24.3 Sec for Async Django, and 33.5 Sec for FastAPI.
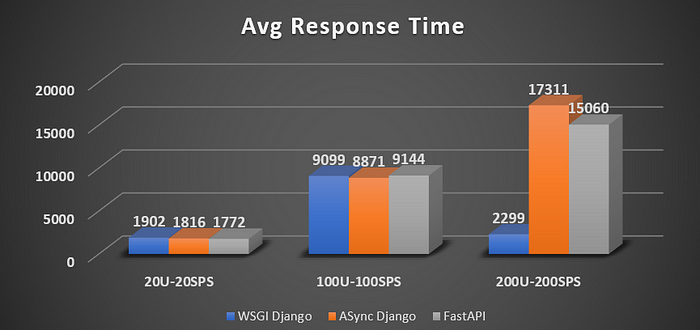

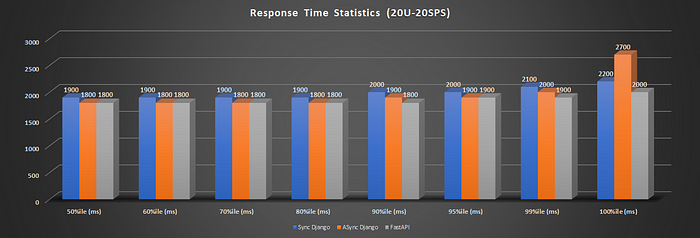
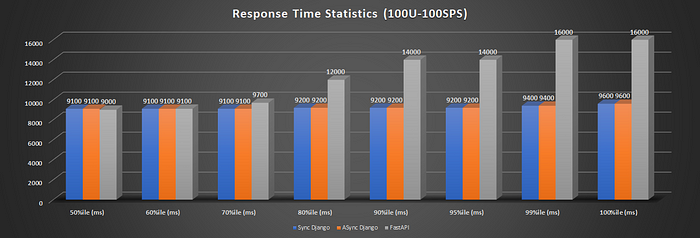
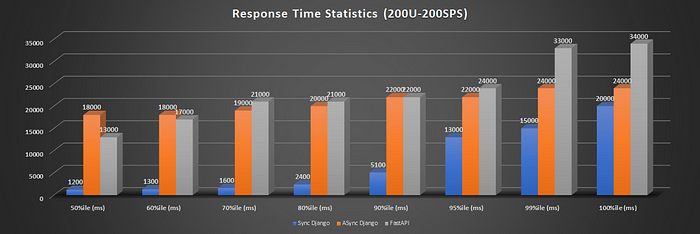
Avg Response Time WINNER: Hard to Decide.Tie between Django Async and FastAPI for low-moderate case. Fast API performs better when load is low — moderate at best. With near-peak and peak load, FastAPI response times are almost doubled. See Fig 6.7,8. Async Django seems to be the winner.
Final Verdict
Django Async seems to be an optimal choice for hosting ML/DL/AI inference models on servers. It's FAST, it's less error-prone, can handle better overload conditions.
HOWWWWEVVER, coding in Async Django-DRF is a nightmare — to put it mildly. If you want to just run few functions, you should be Ok. But, if you want to exploit the Django-type coding, then you are in for a big surprise.
There is no out-of-box Async support for our beloved Django-Rest-Framework (DRF). So, any class-based API views, with serializers cannot be used while exploiting asyncness of Django. Due to this, any validation, input cleansing, and permission checking have to be done manually without the ability to use class-based operations. This increases the burden of additional programming. And good luck trying to use the inbuilt CSRF middleware. We had to disable it to get the Async API endpoint working.
Sync Django or WSGI Django or just the normal Django we have come to know and use all these years, doesn't fall behind much during low-moderate loads. But, the blocking effects of synchronous nature quickly appear during peak traffic — 90% of traffic unserved is simply unacceptable.
FastAPI on the other hand makes exploiting asyncness look like a walk in the park. However, being the young kid in the block, it still lacks some of the amazing things Django-DRF offers. It is going to improve for sure! From the performance standpoint, we didn't even dream that FastAPI would be beaten by Async-Django. Apart from the frameworks, Django and FastAPI, the whole instance is a replica.. all the way from NGINX to Uvicorn server - Same hardware, CPU, etc (unless — process variation corners of the hardware at play — Shout-out to the hardware and VLSI engineers).
Interpreting the performance numbers
— Why these numbers matter? Why can't we just run our ML/DL inference server with a higher configuration system?
These tests were designed to see how does a framework performs given the constraints of the same hardware. Django Async can serve up to 150-168 Users/Sec whereas FastAPI has the same error rate and fails to serve 100 Users/Sec. That's a massive 50–70% difference.
If we had an application that required us to have an inference engine serving a large number of users, then we would put such an inference engine in an autoscaling group orchestrated by Kubernetes, EKS, ECS, Docker Swarm, Fargate Clusters, App Engines, Lamdas, etc. Now, with that in mind:
If we had to serve the same exact number of users, for the same exact time — Then using the above numbers, FastAPI and Sync Django would lead to more 2X the cost that would have incurred if Async Django were to be used.
[Guily as Charged: We do have some of our inference microservice engines in FastAPI — We had jumped the ship due to the hype tide. I guess, now its time to change the framework]
Final Thoughts
We hope that Django Async support grows and primarily Django DRF gets Async support. (DRF devs.. are you listening??) We also hope that FastAPI keeps growing and the performance issues are addressed.
Annexure and Resources:
You can test the above-mentioned servers at the following link:
- Sync Django: https://app.dl-django-uwsgi.aibharata.com
- Async Django: https://app.dl-django-asgi.aibharata.com
- FastAPI: https://app.dl-fastapi-asgi.aibharata.com
API Request:
curl --location --request POST '<URL>/api/predict' --form 'files=@"/C:/Downloads/SampleImages/cat.jpg"'
We will keep these links active, until the data movement and network usage cost doesn't blow up…!! Do keep in mind, that no scaling or no ELB enabled, so if you are unable to access it; that means someone else is stress testing it.. !!
Codes and Code Link:
All the codes used in this experiment are available at
4 Different ways of serving a DL/ML inference app are available in the repo.
Raw Reports:
Raw locust reports can be accessed using the below links:
Async Django Report
Sync Django Report
FastAPI Report
Author: Vinayaka Jyothi
Linkedin: https://www.linkedin.com/in/vinayakajyothi/
Company Linkedin: https://www.linkedin.com/company/aibharata/
Company Website: https://www.aibharata.com
